Segmentez les clients pour un site de e-commerce
Olist, un site de e-commerce nous charge d'effectuer une segmentation (clustering) de la clientèle dans le but de fournir des perspectives approfondies sur les différents profils d'utilisateurs. Malgré la disponibilité restreinte de données, notre approche se concentre sur l'utilisation d'algorithmes non supervisés pour maximiser l'information tirée de ces données limitées. En parallèle, notre second objectif est de déterminer la fréquence optimale de ré-entraînement du clustering afin de doter Olist d'outils analytiques robustes, lui permettant de mieux appréhender la diversité de sa clientèle, d'adapter ses stratégies commerciales et de perfectionner son service en ligne.
Afin de réaliser cette tâche, Olist nous a fourni une série de 9 ensembles de données comprenant des informations sur les commandes effectuées entre septembre 2016 et novembre 2018. Parmi ces 9 ensembles, nous n'utiliserons qu'une sélection spécifique pour notre analyse.
Afin de procéder à la segmentation par clusters, notre approche débute par la création de features significatives. Pour cela, nous avons opté pour l'analyse RFM (récence, fréquence, montant) :
- La récence, mesurée en jours, reflète le laps de temps entre la date de la dernière commande du client et la date de la commande la plus récente.
- La fréquence représente le nombre total de commandes réalisées par le client.
- Le montant correspond à la somme totale des paiements effectués par le client. Cette méthodologie nous permet de définir des paramètres significatifs pour le regroupement des clients en clusters pertinents.
Ce projet m'a permis d'explorer et de tester les différentes techniques de machine learning non supervisé, telles que les méthodes de réduction de dimension (PCA, NMF, t-SNE), qui s'avèrent très utiles pour la représentation des données, ainsi que les différentes techniques de clustering (K-means, DBScan, Ward Clustering). Un des défis en machine learning non supervisé réside dans la difficulté à évaluer un modèle, étant donné l'absence d'étiquetage des données et l'absence de binarité dans l'évaluation d'un clustering. Heureusement, il est possible d'évaluer un clustering en définissant des métriques telles que la variance inter-cluster et la variance intra-cluster, l'indice de Davies-Bouldin, le coefficient de silhouette ou encore le score ARI. Un moyen efficace d'optimiser un clustering est de minimiser la variance intra-cluster tout en maximisant la variance inter-cluster, des situations dans lesquelles les métriques susmentionnées présentent des valeurs favorables. Cette expérience a renforcé ma compréhension des nuances et des défis inhérents au domaine du machine learning non supervisé.
Au final, on obtient une segmentation en 5 clusters. Nous avons appliqué un alorithme de réduction de dimension pour projeter les données sur leur premier plan principal. On peut ensuite aisémant étudier les caractéristiques de ces 5 clusters :
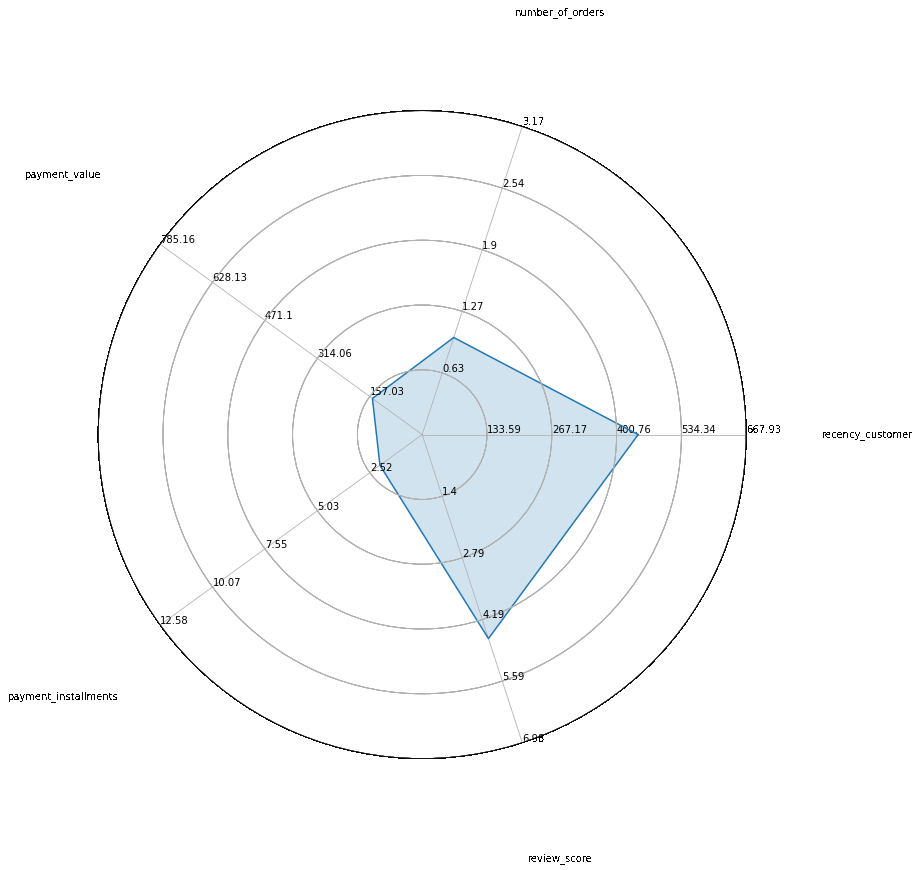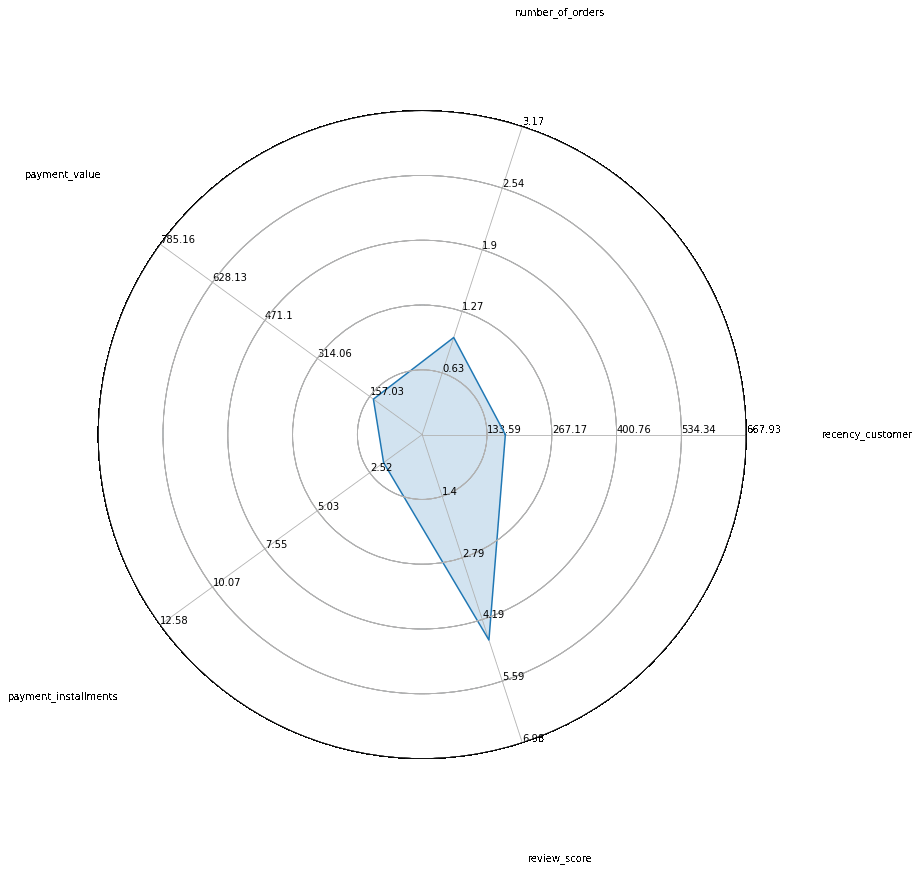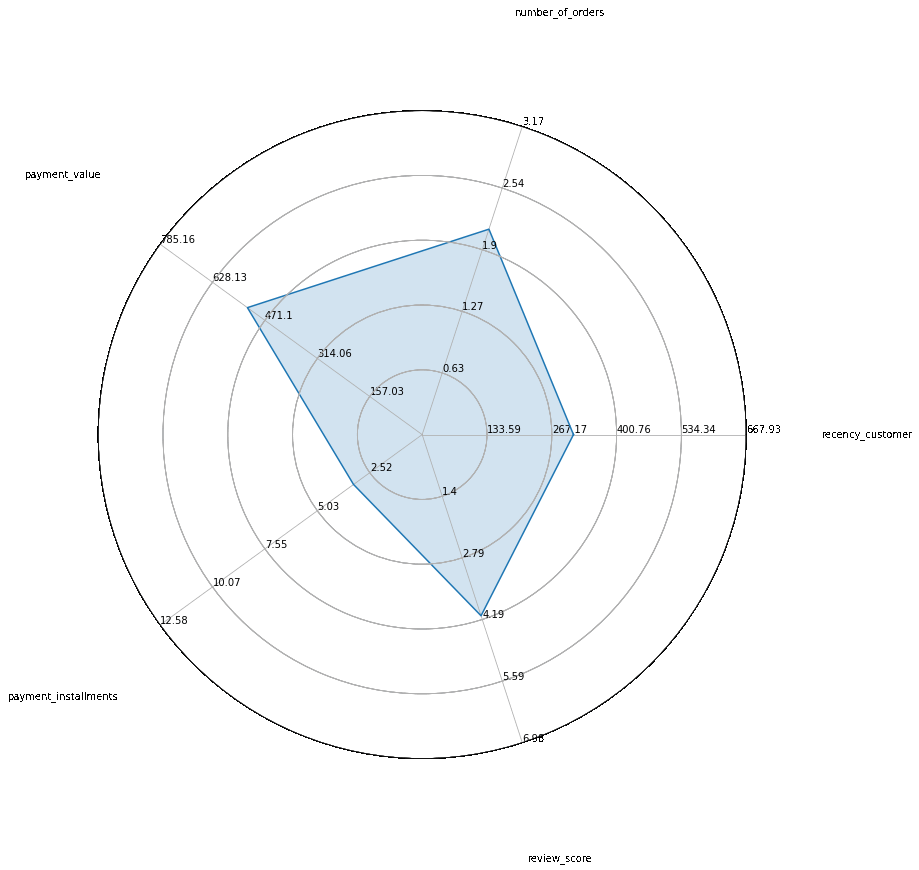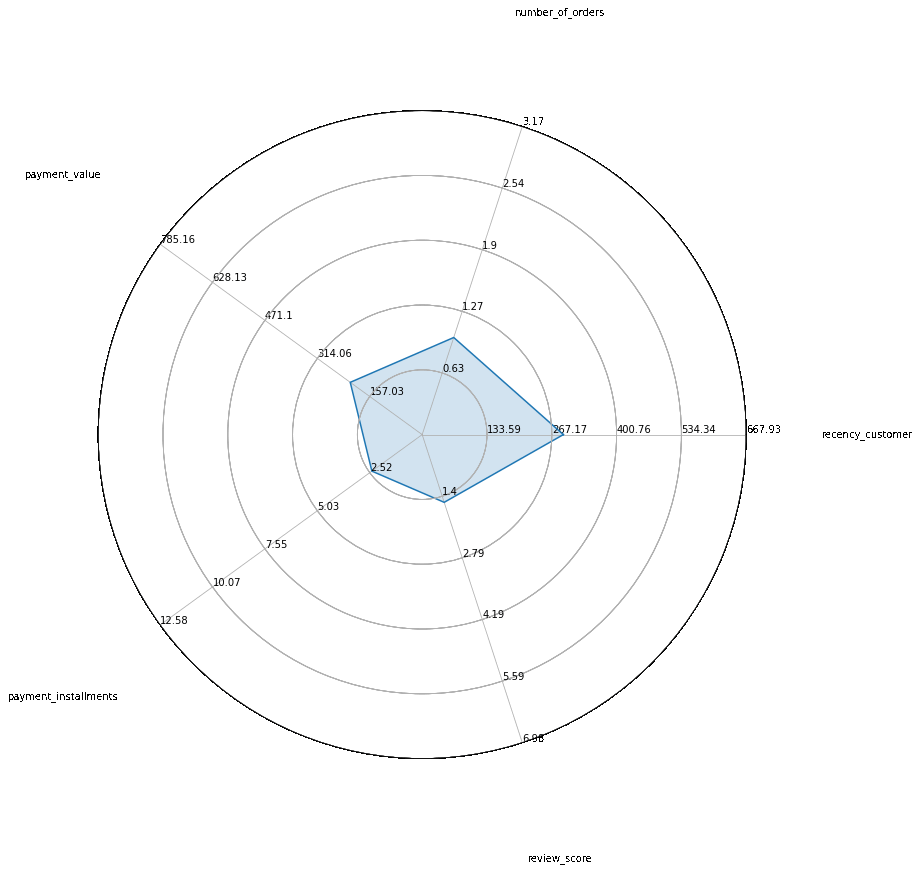
En résumé, cela signifie que l’analyse a permis d’identifier 5 profils de clients aux caractéristiques différentes que Olist pourra utiliser pour cibler ces campagnes marketing.
Pour plus de détail sur ce projet vous pouvez vous rendre sur le repository Github.
Compétences acquises :
Adapter les hyperparamètres d'un algorithme non supervisé afin de l'améliorer
Évaluer les performances d’un modèle d'apprentissage non supervisé
Transformer les variables pertinentes d'un modèle d'apprentissage non supervisé
Mettre en place le modèle d'apprentissage non supervisé adapté au problème
Sélectionner le nombre de cluster optimal pour un modèle de clustering