Optimisation Énergétique : Déployer un Modèle de Prédiction de la Consommation pour des Bâtiments Écologiques
La ville de Seattle nous a chargés de participer à son initiative visant à devenir neutre en carbone d'ici 2050 en anticipant la consommation d'énergie et les émissions de gaz à effet de serre des bâtiments non résidentiels. Dans cette démarche, nous utilisons les données de consommation des propriétés de Seattle pour les années 2015 et 2016 avec pour contrainte que la prédiction se fondera exclusivement sur les informations déclaratives du permis d'exploitation commerciale.
Python s'impose comme l'outil idéal pour ce projet en raison de son écosystème prolifique et largement accepté dans les domaines de la science des données et du machine learning. La popularité de Python garantit un accès facilité à des bibliothèques spécialisées telles que NumPy, Pandas et Scikit-learn, offrant ainsi une solution exhaustive, cohérente et efficace pour les étapes cruciales du nettoyage, de l'exploration et de la modélisation des données.
Afin d'atteindre cet objectif, nous évaluons plusieurs familles d'algorithmes de machine learning et comparons leurs performances pour sélectionner le modèle le plus performant. Nous débutons en appliquant les compétences acquises lors des deux premiers projets, effectuant ainsi le nettoyage du jeu de données et réalisant une analyse exploratoire approfondie. Ensuite, nous passons à l'étape centrale du projet : choisir le modèle optimal pour prédire la consommation d'énergie des bâtiments non résidentiels.
Ce projet a été une opportunité pour développer mes compétences en analyse de données et en machine learning, en mettant particulièrement l'accent sur les méthodes de régression. J'ai acquis la capacité d'appliquer diverses familles d'algorithmes de régression, tels que la régression linéaire, les machines à vecteurs de support, les réseaux de neurones et les méthodes ensemblistes, tout en évaluant leurs performances. En comparant les modèles à l'aide de différentes métriques (R2, RMSE, temps de calcul) et en utilisant une stratégie d'évaluation basée sur la séparation du jeu de données en un ensemble d'entraînement et un ensemble de test, nous avons pu déterminer le modèle le plus approprié pour prédire la consommation énergétique des bâtiments. Voici les résultats obtenus :
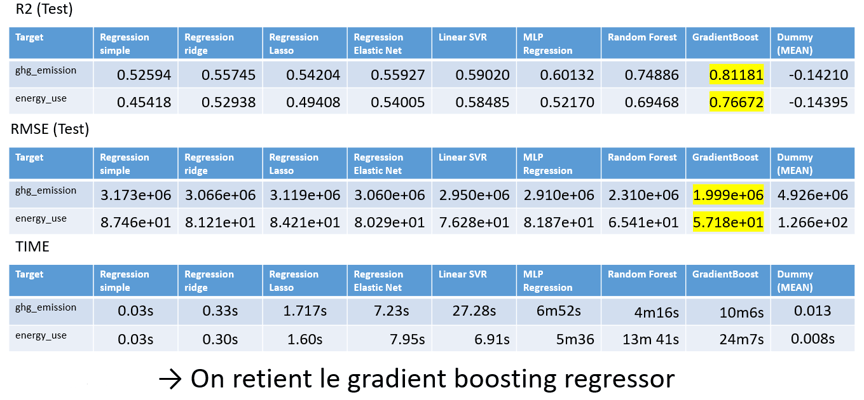
Après comparaison, il est observé que les modèles ensemblistes, en particulier le gradient boosting, démontrent les meilleures performances pour ce type de problème. En conséquence, le modèle retenu pour anticiper la consommation énergétique des bâtiments est le gradient boosting.
De plus, ce projet m'a sensibilisé aux défis spécifiques liés à la création de modèles prédictifs dans le contexte d'objectifs environnementaux ambitieux
Pour plus de détail sur ce projet vous pouvez vous rendre sur le repository Github.
Compétences acquises :
Mettre en place le modèle d'apprentissage supervisé adapté au problème métier
Mettre en place une stratégie de régularisation pour réduire le sur-apprentissage.
Sensibilisation au problème classique de la fuite de données (data leakage)
Transformer les variables pertinentes d'un modèle d'apprentissage supervisé (passage au log, feature engineering, standardisation)
Optimiser les hyperparamètres d'un algorithme d'apprentissage supervisé à l’aide d’une recherche en grille (gridsearch)
Évaluer les performances d’un modèle d'apprentissage supervisé