Implémenter un modèle de scoring pour une institution financière
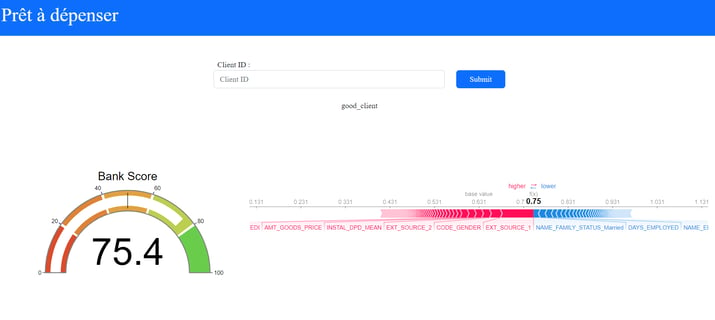
Ce projet s'inscrit dans le cadre d'une mission pour la société financière HomeCredit. Dans le domaine bancaire, la prédiction des défauts de paiement revêt une importance capitale, étant donné que ces incidents sont estimés coûter en moyenne dix fois plus cher qu'un simple refus de crédit. Dans cette perspective, l'objectif est de prédire le risque associé à un nouveau client et pour cela, le modèle développé générera un score client, évalué sur une échelle de 0 à 100, où 100 représente un risque minimal et 0 un risque maximal.
Pour cela, nous disposons d'un jeu de données comprenant huit tables fournies par HomeCredit. Ces tables regorgent d'informations diverses concernant une base d'anciens clients, englobant des variables telles que l'âge, le sexe, le statut familial, les soldes de cartes de crédit, ainsi que les prêts antérieurs octroyés par HomeCredit ou d'autres institutions financières.
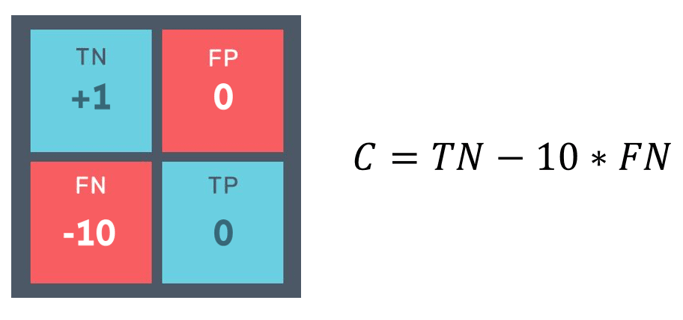
Ce projet aborde une problématique de classification particulière, à savoir un problème de classification binaire déséquilibrée. En effet, la classe positive, représentant les clients en défaut de paiement, est nettement minoritaire (10%) par rapport à la classe négative (90%). Face à cette asymétrie, l'optimisation de la précision (accuracy) n'est plus pertinente. Il devient impératif de définir une métrique personnalisée basée sur des considérations métier, dans notre cas, visant à minimiser les pertes engendrées par les défauts de paiement, et donc à réduire au maximum les faux négatifs.
Par ailleurs, différentes stratégies sont envisageables pour traiter ce type de jeu de données, notamment la génération d'observations artificielles respectant la même distribution de probabilité que notre ensemble de données initial. Cela peut être réalisé à l'aide de méthodes de rééchantillonnage, telles que SMOTE, implémentée dans la bibliothèque Python imbalanced-learn.
Une fois la métrique définie et la stratégie de rééchantillonnage mise en œuvre, nous sélectionnons le modèle de classification et optimisons les hyperparamètres grâce à une recherche en grille. En résultat, nous obtenons un modèle optimisé (LightGBM) pour minimiser les faux négatifs, fournissant une probabilité entre 0 et 1 indiquant la propension du client à être en défaut de paiement. Enfin, pour simplifier l'interprétation, nous calculons un score en prenant le complémentaire de cette probabilité et en le multipliant par 100.
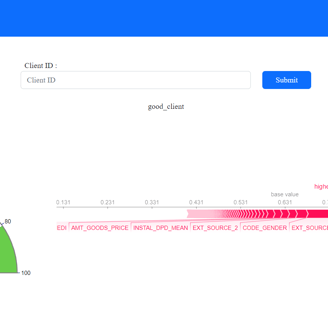
La librairie SHAP (SHapley Additive exPlanations) joue aussi un rôle clé dans notre projet de modélisation de défauts de paiement, en particulier avec le modèle de classification ensembliste LightGBM que nous avons choisi. Les modèles ensemblistes, par leur nature complexe, rendent souvent difficile la compréhension des relations entre les entrées et les sorties. SHAP offre des méthodes « model-agnostic » pour expliquer ces résultats, mettant en évidence l'impact de chaque caractéristique sur la probabilité de défaut de paiement. Pour interpréter localement les scores du modèle, nous utilisons des « force plots » qui illustrent l'écart entre la probabilité de défaut de paiement pour un échantillon donné et la moyenne des probabilités des échantillons de la classe négative. Ainsi, SHAP apporte une transparence cruciale, permettant à l’utilisateur final de comprendre les données clients qui ont le plus influencer le calcul de son score.
L’étape suivante à été le développement d’une API intégrant le modèle ainsi défini en utilisant le framework python FastAPI. La requette communique les données clients sous le format json et le modèle retourne les prédictions de score pour ces clients. Puis à l’aide du framework Flask on développe un dashboard qui a pour but de permettre à un utilisateur non technique d’accéder aux informations du clients, à son score et aux forces plots susmentionnés à partir de son identifiant clients. Enfin, on utilise docker pour conteneuriser le dashboard et l’API et s’assurer la robustesse de l’application et on déploie le tout sur heroku pour que le modèle soit accessible par les utilisateurs finaux.
Pour plus de détail sur ce projet vous pouvez vous rendre sur le repository Github.
Compétences acquises :
Déployer un modèle via une API dans le Web
Réaliser et déployer un dashboard
Utiliser un logiciel de version de code pour assurer l’intégration du modèle
Définir et mettre en œuvre un pipeline d’entraînement des modèles
Définir la stratégie d’élaboration d’un modèle d’apprentissage supervisé
Évaluer les performances des modèles d’apprentissage supervisé
Utiliser la méthode shap d’interprétation local de modèle de machine learning
Gérer les datasets déséquillibrés