Étude Stratégique : Cartographie des Régions Propice à l'Internalisation d'un Centre de Formation
Une institution éducative aspire à une expansion internationale et nous a chargés d'effectuer une analyse en utilisant des données éducatives disponibles librement, issues d'une étude de grande envergure de la banque mondiale (World Bank All Education Statistics All Indicator Query). L'objectif est de déterminer les régions les plus favorables pour envisager une expansion de ses activités.
Pour effectuer notre analyse, on se tourne naturellement vers python et on crée un notebook Jupyter. Python offre une puissante gamme d'outils et de bibliothèques pour l'analyse de données. Pandas facilite la manipulation de données tabulaires, NumPy offre des opérations numériques efficaces, Matplotlib et Seaborn permettent de créer des visualisations. Avec Jupyter, un environnement interactif, Python devient un choix privilégié pour l'exploration, le nettoyage, la visualisation et la modélisation de données.
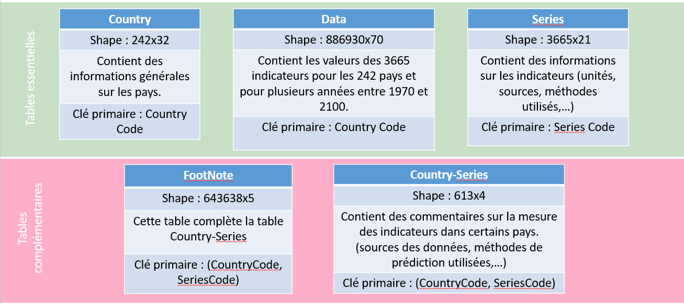
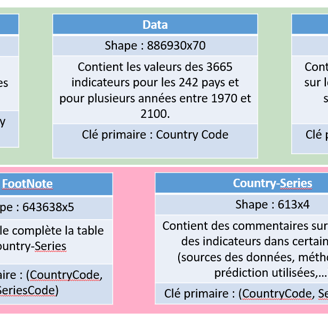
Le projet commence par la compréhension de la base de données EdStats, qui contient plus de 4 000 indicateurs internationalement comparables sur l'éducation, tels que l'accès, l'achèvement, l'alphabétisation, les effectifs enseignants, la démographie, et les dépenses. Les données comprennent également des résultats d'évaluations internationales, des données d'équité issues d'enquêtes ménagères, et des projections jusqu'en 2050.
La base de données, comme souvent, est fragmentée en fichiers CSV, nécessite des jointures pour être complète. Cependant, tous les morceaux ne sont pas toujours utiles, donc seuls les fichiers pertinents sont conservés, et la base est reconstruite à partir de ces fragments.
L'exploration de la base révèle plus de 4 000 indicateurs, renseignés pour la plupart des pays. Une sélection est effectuée en éliminant les indicateurs peu renseignés, puis en choisissant une dizaine d'indicateurs pertinents avec des valeurs historiques et des prédictions sur 30 ans.
Les indicateurs choisis sont agrégés pour simplifier l'interprétation, en regroupant les tranches d'âge sans distinction de genre. Les statistiques pertinentes sont définies en fixant des règles basées sur des références, en l’occurrence sur les valeurs du pays actuel de l'institut.
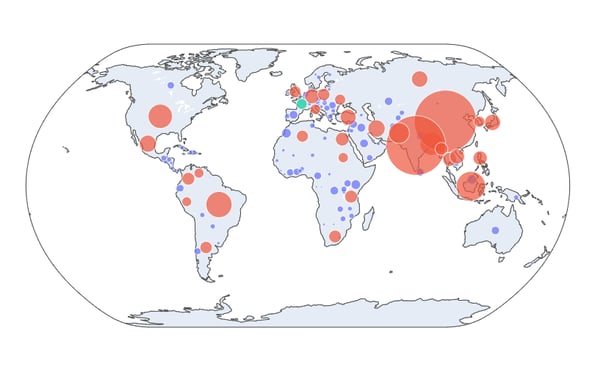
Enfin, des visualisations, comme les cartes à bulles (bubble maps), sont créées pour faciliter la sélection des régions propices à l'implantation.
La carte illustre la référence en vert, les pays affichant des valeurs supérieures en rouge, et ceux avec des valeurs inférieures en bleu. On peut voir que l’Asie du Sud et le continent américain sont des candidats intéressants.
Pour plus de détail sur ce projet vous pouvez vous rendre sur le repository Github.
Compétences acquises :
Maîtriser les opérations fondamentales du langage Python pour la Data Science
Reconstituer une base de données morcelée par jointure
Effectuer une analyse métier pour selectionner les features pertinentes à la résolution d’une problématique
Effectuer une analyse exploratoire des données et nettoyer des données
Effectuer une représentation graphique à l'aide d'une librairie Python adaptée