Développer un Moteur de Classification Innovant pour les Biens de Consommation
Sur la plateforme Marketplace, les vendeurs proposent une variété d'articles, accompagnés d'une photo du produit et d'une brève description. Actuellement, la catégorisation de ces produits repose sur les choix des vendeurs. Cependant, dans le cadre de ce projet, nous aspirons à automatiser ce processus en attribuant automatiquement une catégorie aux produits. Cette classification sera effectuée en exploitant le traitement de l'image et de la description du produit, éliminant ainsi la nécessité de l'intervention manuelle des vendeurs.
À l'instar des projets antérieurs, nous faisons usage du langage de programmation Python pour la mise en œuvre de notre projet actuel. Cette préférence s'explique par la richesse des bibliothèques spécialisées qu'offre Python, particulièrement adaptées au domaine du deep learning. Des outils renommés tels que TensorFlow, Keras, et Transformers sont intégrés dans notre environnement de développement, fournissant des fonctionnalités essentielles pour la création et l'entraînement de modèles complexes. En outre, l'utilisation de librairies comme NLTK (Natural Language Toolkit) simplifie considérablement les étapes de traitement du langage naturel.
Lors de ce projet, nous nous sommes concentrer spécifiquement sur les méthodes d'embedding de données et d'extraction de features, visant à permettre à l'ordinateur de comprendre à la fois les données textuelles et visuelles. Puis nous avons soumis ces données à des algorithmes non supervisés de clustering, avec l'utilisation d'un k-means pour le regroupement et une visualisation en 2D à travers une réduction de dimension par T-SNE. Ce processus vise à simplifier le travail des vendeurs, et ainsi à améliorer significativement la classification des produits sur la plateforme.
Afin de concrétiser la démonstration de notre concept, nous utiliserons un échantillon représentatif de produits. Nous disposons d'une base de données comprenant des informations sur 1050 produits, englobant une image du produit, sa description, sa catégorie, ainsi que diverses autres données telles que l'identifiant, la marque, le prix, les spécifications, etc. Cependant, dans le contexte de cette étude, nous accorderons moins d'importance à ces informations supplémentaires, focalisant davantage notre attention sur la photo du produit et sa description.
D'une part, ce projet m'a offert l'opportunité de me familiariser avec les techniques clés de prétraitement des données textuelles, notamment la tokenisation, la lemmatisation, la stemmatisation, et le POS tagging. Il m'a également permis de découvrir les méthodes d'embedding de données, telles que les approches de type bag of words, englobant le comptage simple (bag of words classique) et le tf-idf. Parallèlement, j'ai exploré des approches d'embedding de type word/sentence, telles que WORD2VEC, BERT, et U.S.E. Ces méthodes visent à créer des représentations vectorielles des différents mots constituant un corpus, rendent possible leur exploitation par un modèle de machine learning.
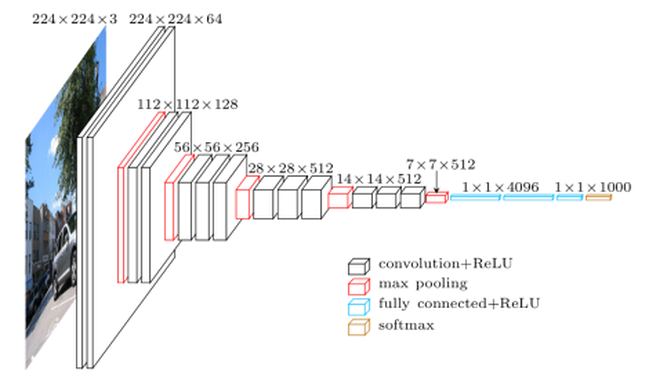
D'autre part, ce projet m'a permis d'explorer les techniques de représentation d'images, communément appelées « computer vision », ainsi que les méthodes d'extraction de features à partir de ces images, permettant de les représenter comme un « bag of features », à l'instar des « bag of words ». J'ai ainsi acquis des connaissances dans la mise en œuvre de méthodes plus anciennes telles que SIFT ou ORB, qui reposent sur la convolution, ainsi que des approches plus modernes basées sur le deep learning, impliquant notamment les réseaux de neurones convolutifs (CNN). Ces derniers, dont les premières couches sont spécifiquement entraînées pour réaliser automatiquement cette extraction de features, ont constitué une part intégrante de mon apprentissage au cours de ce projet. J’ai par exemple eu l’occasion de tester les modèle VGG16 ou encore ImageNet et ResNet :
Enfin, ce projet m'a permis d'acquérir des compétences dans la mise en place de stratégies de Transfert Learning, une approche consistant à utiliser des modèles de deep learning pré-entraînés et à les adapter à notre problème spécifique. Par exemple, une méthode implique de déconnecter les couches "hautes" du réseau de neurones, généralement constituées d'un classifieur (couche fully-connected). Cela permet d'obtenir un extracteur de features performant, pouvant être associé au modèle de notre choix. Une autre stratégie, le fine-tuning total, implique également de déconnecter la couche fully connected du modèle de deep learning, mais dans ce cas, les autres couches sont réentraînées avec notre jeu de données. Le fine-tuning partiel, quant à lui, est une combinaison des deux approches, visant à ne pas figer toutes les couches et à réentraîner certaines (en remplaçant également la couche fully connected par le modèle le plus adapté).
Pour plus de détail sur ce projet vous pouvez vous rendre sur le repository Github.
Compétences acquises :
Prétraiter des données texte et image pour obtenir un jeu de données exploitable
Utiliser des techniques d’augmentation des données
Mettre en œuvre des techniques de réduction de dimension
Représenter graphiquement des données à grandes dimensions
Définir la stratégie d’élaboration d’un modèle d'apprentissage profond
Évaluer la performance des modèles d’apprentissage profond selon différents critères
Mettre en place une stratégie transfer learning