Déployer un modèle dans le cloud
La start-up Fruits! ambitionne de révolutionner le domaine de la cueillette avec le développement de robots cueilleurs intelligents. Afin de susciter l'intérêt du grand public, la société envisage de lancer une application novatrice. Cette application permettra aux utilisateurs d'obtenir des informations détaillées sur n'importe quel fruit simplement en le prenant en photo. Notre mission dans ce projet consiste à concevoir l'architecture big data de cette application révolutionnaire.
Le jeu de données que nous avons utiliser comprenait 82,213 images représentant 120 fruits et légumes. Ces images avaient subi un prétraitement visant à éliminer l'arrière-plan, ne conservant ainsi que le fruit en question et chacune d'elles avait été redimensionnée au format 100 x 100 pixels. Notre approche dans le cadre du projet s’est principalement concentrée sur le prétraitement des images, impliquant une étape d'embedding et d'extraction de features à l'aide d'un CNN (Convolutional Neural Network), plus précisément le modèle ImageNet, suivi d'une réduction de dimension par PCA.
La conception de l'architecture de l'application s'est déroulée sur la plateforme AWS, impliquant l'utilisation de trois services clés. IAM (Identity and Access Management) a été déployé pour la gestion des identités et la sécurité du serveur. EMR (Elastic MapReduce) a été mis en œuvre pour superviser le cluster de serveurs, assurant ainsi une gestion optimale des ressources. Enfin, S3 a servi de solution de stockage pour les données ainsi que pour les scripts nécessaires au bon fonctionnement de l'application. En combinant ces services, nous avons pu construire une architecture répondrant à trois critères essentiels lors de la conception d'un système big data : le passage à l'échelle, la facilité de maintenance, et la facilité d'exploitation des données.
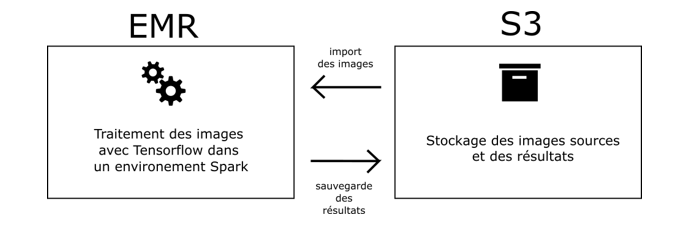
Les étapes de pré-traitement ont été réalisées à l’aide du framework Pyspark, qui est un framework open source rapide et puissant conçu pour le traitement de données à grande échelle. Grâce à ses capacités de traitement distribué, Pyspark permet une manipulation efficace des données, ce qui est particulièrement crucial dans le contexte d'un jeu de données volumineux comme celui que nous manipulons. Le projet nous a ainsi permis de nous familiariser avec les technique de calcul distribué et notamment avec le formalisme map reduce et de l’appliquer concrètement grâce à une librairie spécialisée.
On en a aussi profiter pour réaliser des test de scalabilité en faisant varier la tailles du jeu de données et le nombre de nœuds dans le clusters de serveurs et en comparant les temps d’execution :
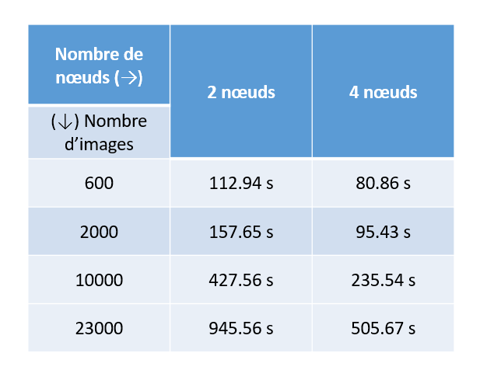
Ce test nous a permis de constater l’existence d’un temps imcompressible (l’overhead) qu’il n’est pas possible de diviser en multipliant les ressources de calcul et qui correspond à la communication entre les nœuds, la synchronisation des processus, et d'autres opérations liées à la coordination des ressources distribuées.
Pour plus de détail sur ce projet vous pouvez vous rendre sur le repository Github.
Compétences acquises :
Utiliser les outils du cloud pour manipuler des données dans un environnement Big Data
Identifier les outils du cloud permettant de mettre en place un environnement Big Data
Paralléliser des opérations de calcul avec Pyspark